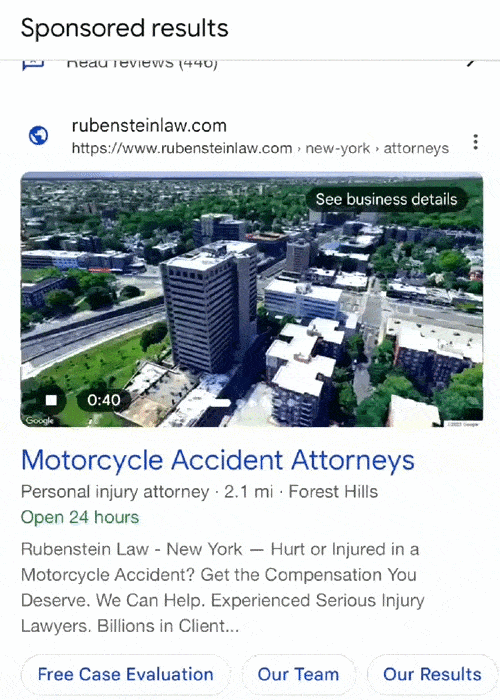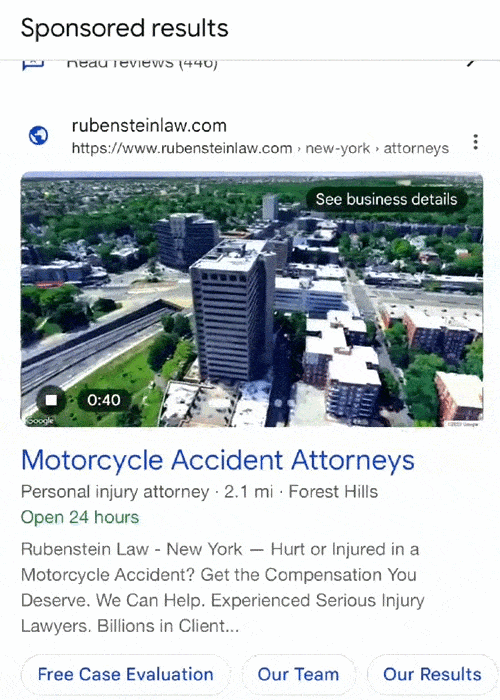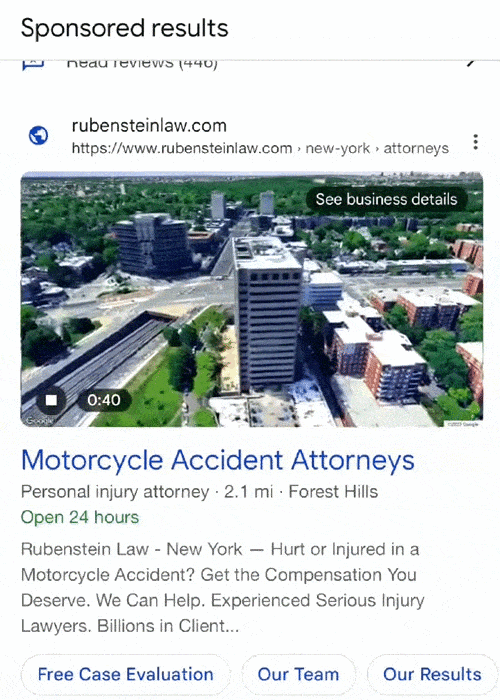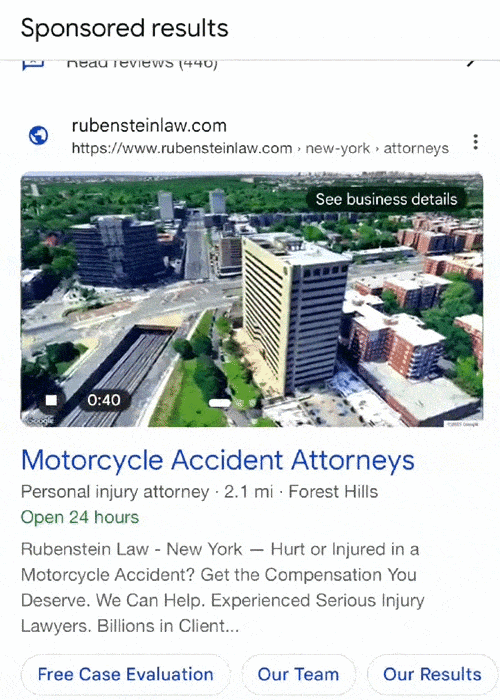
Google has started testing including video ads within its local search results, as shared by Anthony Higman on LinkedIn recently.
Higman reported seeing new “immersive map view videos” popping up with PPC ads appearing in local packs, the group of local results appearing with a map when searching for businesses near a specific location.
The test may signal that the search engine is looking to make its local results more rich, with multimedia options beyond the collection of images brands can upload to their Google Business Profiles.
What To Know
Since the test is very early, there are quite a few questions about how the feature works.
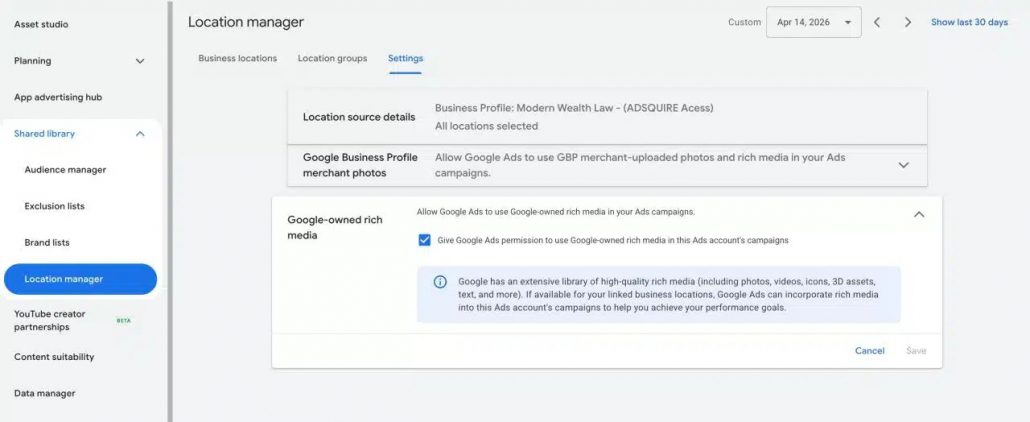
Experts believe the feature may be tied to settings within the Google Ads’ Location Manager. Specifically, it may be enabled through a setting in the shared library that seems to be opted-in by default.
It is also unclear how much freedom advertisers may have with these videos. The current iteration just shows a 360 degree aerial view of the company’s building and it is unknown if Google is considering allowing other types of videos to be included in the local pack. It is also unclear if the video is generated using Google Maps data or if it was rendered by the company associated with the listing.
At the same time, this is a significant shift towards opening the local results to more rich multimedia experiences that could potentially showcase products, locations, and services important to your business.
Additionally, this feature could potentially give a big opportunity to brands looking for a way to stand out to local consumers with eye-catching media.
The test is just starting to appear and it could be some time before it becomes widely available, but this is absolutely something to keep an eye on if you are looking for a competitive edge that will help drive more conversions through local ads on Google.
https://www.tulsamarketingonline.com/wp-content/uploads/2020/01/GoogleRankings.png360640Taylor Ballhttps://www.tulsamarketingonline.com/wp-content/uploads/2018/07/TMO-Logo.pngTaylor Ball2026-04-24 16:19:102026-04-24 16:19:12Google Tests Including Video In Local Search Ads
Google has confirmed it has started a “small and narrow test” using AI to rewrite site headlines in search with AI without any notification to users or website managers.
The confirmation raised eyebrows as it used strikingly similar language as the search company used last year when it confirmed it was rewriting headlines in its Discover feed before making it an official feature a month later.
Google Confirms Rewriting Headlines With AI
According to a report from The Verge, Google has been rewriting headlines in search for several months. Notably, many of the headline rewrites led to misleading or outright unrelated headlines. For example, researchers noted an instance where the headline “I used the ‘cheat on everything’ AI tool and it didn’t help me cheat on anything” to the shorter, less-descriptive headline “‘Cheat on everything’ AI tool.” In another case, it gave an article the headline “Copilot Changes: Marketing Teams at it Again” despite that language never being used in the article.
Sean Hollister described the practice as similar to “a bookstore ripping the covers off the books it puts on display and changing the titles.”
While the AI rewrites seemed to be used most frequently on news sites, The Verge confirmed Google has changed headlines on other types of websites as well.
None of these changes had any notice or disclosure that the headline users were seeing was different from the original headline.
In a statement, Google said it aims to use AI to “identify content on a page that would be a useful and relevant title to a users’ query” and to improve “matching titles to users’ queries and facilitating engagement with web content.”
A Repeating Pattern
While it is not uncommon for Google to test features like this on a limited number of sites, Matt Southern from Search Engine Journal noted that Google’s confirmation to The Verge was eerily similar to how the company addressed using AI to rewrite headlines in Discover.
In December of last year, the company acknowledged it was using AI-generated headlines in a “small UI experiment for a subset of Discover users.”
By January, the company announced this was officially a feature for articles appearing in Discover.
Differences With How Google Previously Rewrote Titles
This is not the first time Google has changed headlines appearing in search. In fact, one study found that more than three-quarters of title tags were changed when they appeared in search results.
However, the new test is unique for the way it is using AI to generate entirely new headlines. In the past, Google would rewrite titles and headlines by pulling from content directly on the related page.
With this new test, Google is moving to create titles entirely from scratch without necessarily using phrasing on webpages, risking creating misleading or unrelated headlines.
This could cause major issues for some publishers, as users will get frustrated and mistrust sites they believe are using misleading or “clickbait” headlines.
https://www.tulsamarketingonline.com/wp-content/uploads/2021/10/Google-Quality-Content.png3501000Taylor Ballhttps://www.tulsamarketingonline.com/wp-content/uploads/2018/07/TMO-Logo.pngTaylor Ball2026-03-23 18:54:202026-03-23 18:54:23Google Is Testing Using AI To Rewrite Headlines For Search
While a growing number of U.S. consumers are using TikTok for search, a new survey suggests the popular social network may not be as strong of a challenger to Google as previously believed.
A new survey from Adobe Express found that the number of people using TikTok for search has grown compared to a 2024 survey from the same company. However, the study found that fewer young users say they prefer TikTok to Google’s search engine.
The Study
The report comes from an Adobe Express survey published earlier this month and conducted in January 2026. It surveyed over 800 consumers and 200 small businesses in the U.S. about their search habits across various platforms including Google, TikTok, and ChatGPT.
It found that 49% of consumers report using TikTok as a search engine, an 8 point increase from 2024. However, the most notable findings were among Gen Z users.
Gen Z and TikTok as a Search Engine
While much has been made about the number of Gen Z users favoring TikTok over Google, the study shows that number is actually falling.
Among Gen Z users who were surveyed, those who said they were more likely to turn to TikTok for a search over Google fell from 8% in 2024 to 4% in 2026.
This isn’t to say Gen Z is using TikTok less for search, though. In fact, 65% of Gen Z users said they use TikTok as a search engine, and 25% said they found it effective for finding information. It’s just that they don’t necessarily prefer TikTok’s search tools over Google’s.
Instead, it seems that Gen Z is adopting a multiplatform approach to search – using the platform they feel is best or most convenient for specific searches.
ChatGPT Shows Growth as a Search Engine
While the number of people who prefer TikTok for search over Google fell, the survey suggests more users of every age group are turning to ChatGPT for search over Google.
According to the survey, 14% of users say they are more likely to use ChatGPT for search than Google. This was true even when broken down by age group, with 12% of Gen Z, 15% of millennials, 15% of Gen Z, and 14% of baby boomers.
What This Means
When a significant number of younger users started reporting using TikTok over Google, it caught the notice of many brands and marketers. However, it appears the situation isn’t as simple as “TikTok will be the next big search engine”. Instead, it appears that users are using a variety of search platforms, with ChatGPT quickly growing as a significant player in search.
It is unclear whether the sale of TikTok’s U.S. operations or changes to the platform contributed to the decrease in those who favor the platform.
For brands looking to supplement their search marketing in the face of falling organic search traffic from Google, the answer seems to be investing in multiple platforms and ensuring they are getting picked up by AI tools – especially ChatGPT. That said, it will still likely be quite some time before any single platform dethrones Google as the biggest search engine.
https://www.tulsamarketingonline.com/wp-content/uploads/2026/02/Gen-Z-and-TikTok-Search.png7201280Taylor Ballhttps://www.tulsamarketingonline.com/wp-content/uploads/2018/07/TMO-Logo.pngTaylor Ball2026-02-27 04:43:362026-02-27 04:43:38Gen Z May Be Pulling Away From Using TikTok Over Google Search
A recent analysis by Datos and SparkToro highlights major changes in how people are searching, largely driven by the widespread implementation of AI across Google’s search systems.
A new study of data from millions of real users found a significant drop in how often people in the United States are making searches on Google compared to just a year previous.
Despite Google’s user numbers remaining stable, data indicates that individual users are performing fewer searches – a trend that has significant implications for traffic to organic results, Google ads, and discoverability on search.
What The Study Says
According to Datos and SparkToro’s report, the average number of desktop Google searches per person has dropped by nearly 20% year-over-year for U.S. users. Notably, this phenomenon is largely limited to American users, while Europe only saw a decline of about 2-3%.
Despite this shift, the report says that the amount of traditional searches has remained largely stable over the past year, accounting for approximately 10% of all U.S. desktop activity.
AI Overviews Credited With Reducing Searches Per User
Based on their analysis, Datos largely credits AI with changing how people are searching.
The primary reason behind the change is that users are increasingly getting the information they need with fewer queries. It is believed this is because AI-powered results and instant answers reduce the need for follow-up searches.
While repeat or follow-up searches have seen significant drops, searches that don’t typically result in a click to a website remain high, indicating people are still relying on Google to find information. They are just getting the information more quickly, and largely without clicking through to websites.
While AI is largely credited with the shifts away from repeated searches or follow-up queries, the study emphasizes that users are largely avoiding dedicated AI search tools. Dedicated AI search tools currently account for less than 1% of total desktop activity in the U.S., and the study notes that Google’s “AI Mode” accounts for a tiny percentage of overall usage.
Other Notable Findings
The report largely focuses on the shift in searches per user, but it mentions a few other notable changes in search behavior.
Most significantly, Datos found that users are turning to longer, more complex queries to find the information they need. Specifically, users are more frequently using longer search phrases, typically between six to nine words, when searching. This means keywords are getting longer and shows that businesses should adapt the keywords they focus on accordingly.
The report also shows that when people do click through to a website from Google’s search results, they are increasingly going to one of a handful of websites. Instead of varying search results, the majority of clicks are going to YouTube, Reddit, Amazon, and Facebook.
The Takeaway
The sharp decline in searches per user in the U.S. reflects a new phase in search behavior. Increasingly, AI-powered instant answers are changing how users engage with search engines, often eliminating the need for multiple searches or clicks on external sites. For businesses, this means it is more crucial than ever to diversify the channels you are marketing on, rather than relying strictly on search to drive organic traffic.
https://www.tulsamarketingonline.com/wp-content/uploads/2026/01/Google-Searches-Down.png6751200Taylor Ballhttps://www.tulsamarketingonline.com/wp-content/uploads/2018/07/TMO-Logo.pngTaylor Ball2026-01-30 20:51:392026-01-30 20:51:41U.S. Google Searches Per Person Dropped Sharply in 2025
New directions given to Google’s quality raters tell them to look for signs that a page’s main content is AI-generated or otherwise made using automated tools. If a page is found to be primarily made with AI, according to Google’s John Mueller, raters are asked to rate it as “lowest quality.”
Though this policy shift was apparently part of the January 2025 Search Quality Rater Guidelines update, Mueller first publicly revealed it this week while speaking at Search Central Live Madrid.
Why This Matters
Though Search Quality Raters do not directly affect Google’s search results, their work is used to improve Google’s algorithms. The way they are asked to rank pages typically reflects Google’s overall internal guidelines.
Here’s what Google had to say when they updated the raters’ guidelines in January:
“As a reminder, these guidelines are what are used by our search raters to help evaluate the performance of our various search ranking systems, and their ratings don’t directly influence ranking. The guidelines share important considerations for what content is helpful for people when using Google Search. Our page on how to create helpful, people-first content summarizes these concepts for creators to help them self-assess their own content to be successful in Google Search.”
If Google is instructing its raters to give AI-generated content, it is a sign that the company is hardening its stance on AI content and moving to reduce its presence in search results.
AI content has always been a risky prospect when it comes to SEO, but this is the one of the most significant signs we’ve seen from Google itself that AI-generated content may be unwelcome in search results.
According to Brendon Kraham, the vice president of global search ads and commerce, Google Ads is gearing up for an AI-led “seismic shift” in how people use the internet.
In an interview with MediaPost, Kraham recently discussed Google Ads’ plans for 2025 including how it plans to adapt to the growing integration of AI in nearly every facet of technology.
Why AI Is The Focus In 2025
Kraham says we are in the middle of a transformation in discovering information and interacting with businesses that is even bigger than the mobile revolution.
As he said:
“We’re in the midst of a massive shift toward AI, and frankly, it’s even bigger than the mobile revolution was. It’s about using AI to fundamentally improve how people search for information and connect with businesses.”
Google has to adapt to this on multiple fronts.
“For users, this means getting better answers to their questions, whether they’re simple or complex. From a business perspective, this AI-powered approach is going to drive a significantly better ROI for advertisers.”
How Kraham Sees 2025
When asked about his predictions for the new year, Kraham lays out three main areas that Google is focused on moving forward.
The evolution of search behavior beyond traditional keywords
“This means moving beyond simple keywords and embracing a multimodal search landscape where visuals, context, and even our surroundings play a crucial role in how we find what we need. For marketers, this means adapting to a more nuanced understanding of consumer behavior, where capturing attention and fostering genuine engagement will be paramount.”
The development of AI-powered creative tools for marketers
“This new era of search and ads means we will witness a surge in marketers embracing AI-powered tools — not to replace their creative spark, but to amplify it. Imagine personalized creative solutions that scale effortlessly, unlocking new avenues for expression and delivering measurable results.”
Integrating enhanced measurement capabilities across all digital channels
“Third, in 2025, measurement will be everything. Marketers will need to get laser-focused on their data, figuring out how to connect the dots as users move between searching, streaming, scrolling, and all those different ways of interacting online.”
Google has already been aggressively pursuing the development of AI tools in every area of its platform. Kraham indicates this is only going to accelerate further in the coming year, with new AI developments coming for Performance Max ads, Demand Gen ads, and Google Search products.
https://www.tulsamarketingonline.com/wp-content/uploads/2019/02/GoogleAdsGoogleAdwordsManagementPageFeaturePicture2.jpg4001000Taylor Ballhttps://www.tulsamarketingonline.com/wp-content/uploads/2018/07/TMO-Logo.pngTaylor Ball2025-01-03 18:38:442025-01-03 18:38:45Google Ads Exec Talks AI and Major Developments Coming in 2025
In a wide-ranging interview with The New York Times, Google CEO Sundar Pichai said he expects that search will “change profoundly” in 2025 led by advancements in AI and increasing competition from AI search, social media, and hardware advancements.
Below, we’ve collected highlights from the interview that may give us a peak at Google’s plans for 2025 and beyond.
Google Aims To Be a Leader With AI Development
When asked about where Google is today in comparison to the rest of the market, Pichai emphasized that the company is in the early stages of developing radically powerful new AI tools. Additionally, he emphasized that AI developments that may not seem connected to the company are largely built on the back of research and development made possible with Google’s open-sourced technologies.
“Look, it’s a such a dynamic moment in the industry. When I look at what’s coming ahead, we are in the earliest stages of a profound shift. We have taken such a deep full stack approach to AI.
…we do world class research. We are the most cited, when you look at gen AI, the most cited… institution in the world, foundational research, we build AI infrastructure and when I’m saying AI infrastructure all the way from silicon, we are in our sixth generation of tensor processing units. You mentioned our product reach, we have 15 products at half a billion users, we are building foundational models, and we use it internally, we provide it to over three million developers and it’s a deep full stack investment.
We are getting ready for our next generation of models, I just think there’s so much innovation ahead, we are committed to being at the state of the art in this field and I think we are. Just coming today, we announced groundbreaking research on a text and image prompt creating a 3D scene. And so the frontier is moving pretty fast, so looking forward to 2025.”
Using AI To Enhance Search Instead of Replace It
Increasingly, AI is viewed by many as a competitor to traditional search, leading the interviewer to ask what Google is doing to protect the “blue link economy” in order to not “hurt or cannibalize” its search engine and the market around it.
In response, Pichai discussed how AI has been a major part of Google’s development for longer than most people realize. Going back as far as 2012, AI has been part of Deep Neural Networks used to identify speech and images. Since then, artificial intelligence has been a core part of the search engine’s development.
“The area where we applied AI the most aggressively, if anything in the company was in search, the gaps in search quality was all based on Transformers internally. We call it BERT and MUM and you know, we made search multimodal, the search quality improvements, we were improving the language understanding of search. That’s why we built Transformers in the company.
So and if you look at the last couple of years, we have with AI overviews, Gemini is being used by over a billion users in search alone.”
Where Is Search Going In 2025?
Looking forward, Pichai says he believes Search will be radically changing – and soon. While he says that advancement is becoming more difficult because the easiest innovations have already been done, he still believes that people will be surprised at how much is coming in just the first part of 2025.
“And I just feel like we are getting started. Search itself will continue to change profoundly in 2025. I think we are going to be able to tackle more complex questions than ever before. You know, I think we’ll be surprised even early in 2025, the kind of newer things search can do compared to where it is today…
I think the progress is going to get harder when I look at 2025, the low hanging fruit is gone.
But I think where the breakthroughs need to come from where the differentiation needs to come from is is your ability to achieve technical breakthroughs, algorithmic breakthroughs, how do you make the systems work, you know, from a planning standpoint or from a reasoning standpoint, how do you make these systems better? Those are the technical breakthroughs ahead.”
Will AI Replace Traditional Search?
As increasing numbers of people seem to be relying on AI tools to get quick answers instead of using traditional search tools, some have suggested that AI could eventually replace search as we know it. At the same time, there are concerns that AI may be delivering less reliable or accurate answers, which Pichai believes will ensure that Google’s search tools remain relevant if not more valuable.
“In a world in which you’re flooded with like lot of content …if anything, something like search becomes more valuable. In a world in which you’re inundated with content, you’re trying to find trustworthy content, content that makes sense to you in a way reliably you can use it, I think it becomes more valuable.
To your previous part about there’s a lot of information out there, people are getting it in many different ways. Look, information is the essence of humanity. We’ve been on a curve on information… when Facebook came around, people had an entirely new way of getting information, YouTube, Facebook, Tik… I can keep going on and on.
…I think the problem with a lot of those constructs is they are zero sum in their inherent outlook. They just feel like people are consuming information in a certain limited way and people are all dividing that up. But that’s not the reality of what people are doing. “
The full interview touches on several other questions including potential upcoming regulations, how the search engine views its responsibility towards creators, and other Google platforms like YouTube’s future direction. You can watch it here or below:
https://www.tulsamarketingonline.com/wp-content/uploads/2020/01/GoogleRankings.png360640Taylor Ballhttps://www.tulsamarketingonline.com/wp-content/uploads/2018/07/TMO-Logo.pngTaylor Ball2024-12-20 17:30:372024-12-20 17:30:39Google’s CEO Gives Wide-Ranging Interview On The Future of Google and Search
This week Google announced that it now supports the AVIF file format, making the format eligible to be shown in Google Search and Google Images. Now that the search engine can index and display the popular file format, it will likely become the standard for lightweight high-quality images online quickly.
What Is The AVIF File Format?
AVIF (AVI Image File Format) is a relatively new open-source file format used for images, that can deliver the same quality images as JPEGs or PNGs in remarkably smaller file formats (up to 50% smaller than a comparable JPEG).
Notably, the format seems to combine all the most notable features of other popular image formats. AVIF supports the use of transparency like PNG and even has a higher dynamic range level, allowing for deeper blacks in images. Like GIFs, also allows for the creation of animated images.
What About WebP?
Another newly popular image file format, WebP, might seem like a competitor to AVIF but both formats offer their unique benefits which make them suited for specific needs.
WebP is an ideal format for lossless images – typically used when an image must be of the absolute highest quality possible. On the other hand, WebP is not nearly as small as AVIF, so it is not ideal for those focused on maintaining fast loading speeds.
Why The AVIF File Format May Help SEO
Over the last few years, Google has increasingly emphasized website speed as a major factor it considers when ranking websites.
The search engine has begun using a selection of metrics that measure different aspects of site speed, known as Core Web Vitals.
Because the AVIF file format allows for smaller image sizes, it can help reduce loading speeds on web pages and potentially improve your online rankings.
In an environment where any edge against the competition can be the difference to help you get the top spot, sites will quickly be moving to adopt the format now that Google supports it.
https://www.tulsamarketingonline.com/wp-content/uploads/2024/08/Google-Images.png4201200Taylor Ballhttps://www.tulsamarketingonline.com/wp-content/uploads/2018/07/TMO-Logo.pngTaylor Ball2024-08-30 19:59:072024-08-30 19:59:09Google Now Supports The AVIF File Format Making It The Best Format For SEO
Google is making a big change to its Core Web Vitals ranking signals soon, as the company announced that the new Interaction to Next Paint (INP) signal will replace the First Input Delay (FID) on March 12.
The new INP metric measures the amount of time between when a user interacts with a web page (for example, by clicking a button) to when a browser begins rendering pixels on the screen.
Though FID measured a similar time between user input and browser rendering, Google says INP captures interactivity in ways that were not possible previously.
The History Behind FID and INP Metrics
FID has been a metric used by Google to rank sites since the debut of Google’s Core Web Vitals in 2018. However, Google quickly began to see that this metric didn’t fully capture user interactions as they had hoped.
This led to Google introducing INP as an experimental or “pending” metric in 2022. Now, almost 2 years later, Google has decided to fully replace FID with the INP metric in March.
What You Should Do
Before March, it is recommended that website managers ensure their site is meeting the threshold for a “good” INP performance.
If you do not meet this mark, Google suggests optimizing your site with these strategies:
Evaluate your site’s performance using tools such as PageSpeed Insights or the Google Chrome User Experience Report.
Identify issues that may be slowing down INP, like extended JavaScript tasks, excessive main thread activity, or a large DOM.
Optimize issues based on Google’s optimization guides for the specific issue.
As Google’s ranking algorithms evolve, this and other ranking signals will likely be updated or replaced. This emphasizes how important it is to use the latest optimization standards and to ensure a smooth user experience if you want your business to be easily found online.
https://www.tulsamarketingonline.com/wp-content/uploads/2021/05/Google-Page-Experience-Desktop1.jpg343720Taylor Ballhttps://www.tulsamarketingonline.com/wp-content/uploads/2018/07/TMO-Logo.pngTaylor Ball2024-02-01 19:26:312024-02-01 19:26:34Google To Replace a Core Web Vital Ranking Signal In March
The Google SEO Starter Guide is designed to help individuals and organizations quickly learn the most important steps necessary for getting their websites ranking within Google Search.
While the guide reportedly maintains a 91% approval rating, it has largely gone without updates for several years but that will be changing soon.
In a recent episode of Google’s “Search Off The Record” podcast, the company’s Search Relations team discussed plans to update the SEO Starter Guide, including talking about what would and would not be included in the revised document.
Discussions like this are great for seeing how SEO is talked about within the search engine and learning what the company prioritizes when ranking sites along with identifying SEO myths that might lead you astray when optimizing your own site.
So, what’s changing in the revised SEO Starter Guide?
HTML Structure
One topic the group discussed was the importance (or lack thereof) of HTML structure when it comes to online rankings.
While the team agreed that using proper HTML structure can help with online rankings, they indicated the guide will clarify that these are not all that important in the grand scheme.
As Google’s Gary Ilyes said:
“Using headings and a good title element and having paragraphs, yeah, sure. It’s all great, but other than that it’s pretty futile to think about how the page… or the HTML is structured.”
Branded Domain Names vs Keyword Rich Domain Names
SEO experts have been increasingly debating whether it is better to focus on your existing branding when establishing a domain name, or if domains perform better when including specific keywords.
According to the Google team, the new guide will clarify this by indicating that brands should focus on including branding in their domains over using keywords. The thought process shared by those in the discussion was that establishing a memorable brand will have a more long-term impact than trying to optimize your domain specifically for search engines.
Debunking SEO Myths
Lastly, the group said one thing they want to improve in the document was how it addressed widespread SEO myths and misconceptions.
For example, everyone agreed that the SEO Starter Guide should specifically debunk the idea that using Google products while creating or optimizing your site will improve search rankings.
They indicated they would address this myth and several others to prevent people from optimizing their site based on misinformation found elsewhere online.
https://www.tulsamarketingonline.com/wp-content/uploads/2024/01/Google-Search-Off-The-Record-Banner.jpg253939Taylor Ballhttps://www.tulsamarketingonline.com/wp-content/uploads/2018/07/TMO-Logo.pngTaylor Ball2024-01-30 22:20:342024-01-30 22:20:36What’s Changing The Updated SEO Starter Guide From Google?